
De online tool UDPipe Frysk kent woordsoorten toe aan teksten in het Fries. Een dergelijke basistool ontbrak nog voor de tweede rijkstaal.
Onlangs verscheen de eerste update van de webapp UDPipe Frysk, die eind januari werd gelanceerd. Deze tool maakt taalkundige analyse van Friese teksten mogelijk. In de ingevoerde tekst worden de losse tokens (woorden) herkend en voorzien van lemma’s en woordsoorten (POS-tags).
Webapp
“Een dergelijke basistool voor taalkundig onderzoek bestond nog niet voor de tweede rijkstaal in Nederland, het Fries”, vertelt Hans Van de Velde, die als projectleider aan de Fryske Akademy verantwoordelijk was voor de ontwikkeling van de tool. “POS-tags zijn belangrijk, omdat woordsoorten soms contextafhankelijk zijn. In de zin ‘De bern krige iisfrij’ (‘De kinderen krijgen ijsvrij’) is iisfrij bijvoorbeeld een zelfstandig naamwoord, maar in de zin ‘De mar is hielendal iisfrij’ (‘Het meer is volledig ijsvrij’) een bijvoeglijk naamwoord.”
Onderzoekers kunnen de webapp gebruiken voor onderzoek naar bijvoorbeeld taalverandering, syntactische verhoudingen, auteursherkenning, sentiment-analyse of voor de ontwikkeling van automatische vraag-antwoordsystemen. Van de Velde: “De gebruiker typt zelf een Friese tekst in, uploadt deze of voert een Friese website in.” Hierna verschijnt een tabel met voor elk token het lemma en de woordsoort. Deze output kan vervolgens in verschillende formaten (txt, excel, CoNLL-U) gedownload worden voor verdere analyse.”
Wilbert Heeringa, programmeur bij de Fryske Akademy, ontwikkelde de pijplijn, samen met Gosse Bouma van de Rijksuniversiteit Groningen. Martha Hofman (Fryske Akademy) helpt bij het handmatig annoteren van het trainingscorpus. Heeringa gebruikte het project Universal Dependencies (UD). “Dat project ontwikkelt een universeel annotatieschema dat cross-linguïstisch vergelijken mogelijk maakt. Zo kunnen vergelijkbare constructies in verschillende talen op een consistente manier worden geannoteerd, terwijl ook taalspecifieke annotaties worden toegestaan als die nodig zijn.”
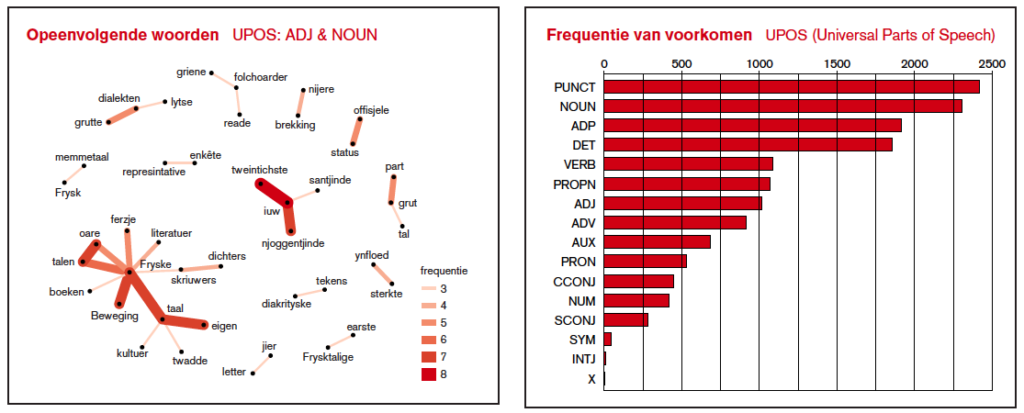
1.547 zinnen
Heeringa trainde de UDPipe Frysk met 1.547 zinnen uit het Oersettercorpus. Dit corpus is in 2012 ontwikkeld voor Oersetter, een automatische vertaalservice voor het Fries en het Nederlands. Het bevat onder andere nieuwsberichten, romans, wetenschappelijke teksten en historisch-culturele teksten.
In de eerste update, die half mei verscheen, is dit trainingscorpus verder uitgebreid met meer zinnen. Bovendien zijn er data toegevoegd die dependency parsing mogelijk maken, zodat ook de grammaticale structuur van een zin met de onderlinge relaties tussen woorden in kaart gebracht kan worden. Ten slotte wordt ook gewerkt aan een analyse van de kwaliteit van de POS-tagging. UDPipe Frysk is mede tot stand gekomen dankzij financiering van CLARIAH-PLUS.