Door taal- en semantische webtechnologie te combineren, wil Marieke van Erp (DHLab, KNAW Humanities Cluster) de mogelijkheden van het Digital Humanities-onderzoek vergroten.
Met taaltechnologie kun je allerlei informatie uit teksten halen. Toch is Marieke van Erp, hoofd van het DHLab, vooral geïnteresseerd in de vragen die daarna komen: Hoe verhoudt die informatie zich tot elkaar en wat vertelt het ons over de wereld? Met de huidige technologie is die vraag vaak nog moeilijk te beantwoorden, maar Van Erp wil hier verandering in brengen. Dit jaar kreeg zij een ERC Consolidator Grant waarmee ze de komende vijf jaar fundamenteel onderzoek gaat doen naar het analyseren van historische teksten met computergestuurde technieken.
Semantisch web
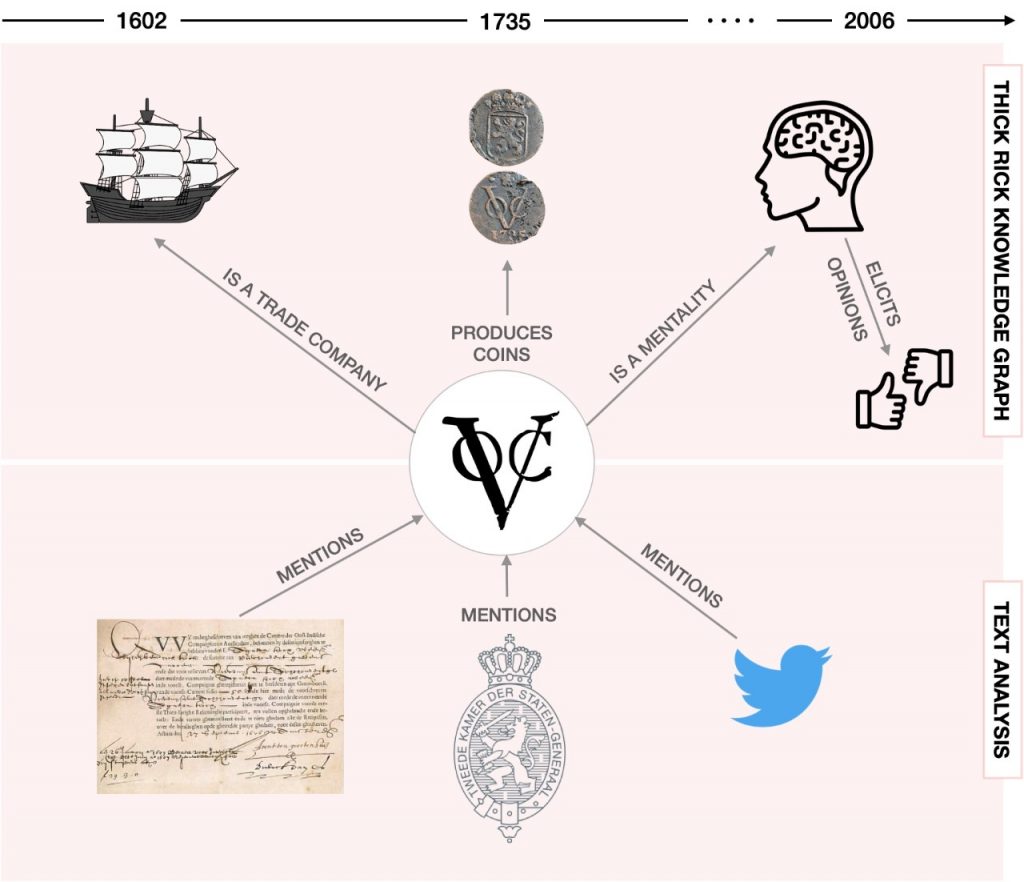
In het geesteswetenschappelijk onderzoek staan concepten centraal die voortdurend veranderen, legt Van Erp uit. Daardoor kun je de informatie niet opslaan in een statische database. “Neem de VOC. Dat was in het oprichtingsjaar 1602 een heel andere organisatie dan in 1798, het jaar van opheffing. Of het concept Nederland: niet alleen de grenzen zijn in de loop van de tijd veranderd, maar ook de geopolitieke entiteit. En ook personen hebben door de jaren heen verschillende rollen. Hoe ga je ermee om als je dit soort informatie wilt analyseren vanuit een historisch perspectief?”
Voor Van Erp ligt het antwoord in het combineren van taaltechnologie en het semantisch web. Ook binnen het project Odeuropa, waarbij gedigitaliseerde erfgoedcollecties worden doorzocht op geurbeschrijvingen, maakt de onderzoeker gebruik van deze techniek. Daarbij wordt informatie uit een tekst opgeslagen via zogenaamde semantische webmodellen, of ‘knowledge graphs’. Het is een groot informatienetwerk, dat een beetje vergelijkbaar is met de organisatie van ons brein.
Oneindige verbindingen
Elk knooppunt in dit netwerk is met drie andere concepten verbonden. De onderzoeker legt uit hoe zo’n kenniseenheid eruit ziet: “Het zijn allerlei losse feitjes: Arnold Schwarzenegger (1) is geboren in (2) Oostenrijk (3). Oostenrijk (1) ligt in (2) Europa (3). Europa (1) is een (2) werelddeel (3). Aan elk knooppunt in het netwerk kun je informatie blijven toevoegen. Hele databases die op deze manier zijn georganiseerd kun je aan elkaar koppelen, en dan heb je opeens allerlei informatie die je kunt bevragen. De tijdsdimensie kun je toevoegen door elk knooppunt een tijdslimiet mee te geven.”
Behalve goed gedocumenteerde feiten, wil Van Erp ook onderbelichte feiten uit de geschiedenis kunnen toevoegen aan zo’n informatienetwerk. “Op de Banda-eilanden heeft de VOC verschrikkelijke dingen gedaan, die nu niet goed zijn gedocumenteerd. Ook die informatie wil ik toevoegen, zodat we een completer beeld krijgen van de geschiedenis, vanuit meerdere perspectieven. Uiteindelijk moet het een blauwprint van stukjes software opleveren, zodat dit soort technologie gedeeld kan worden.”